User
Interface |
| Welcome page & Getting started guide |
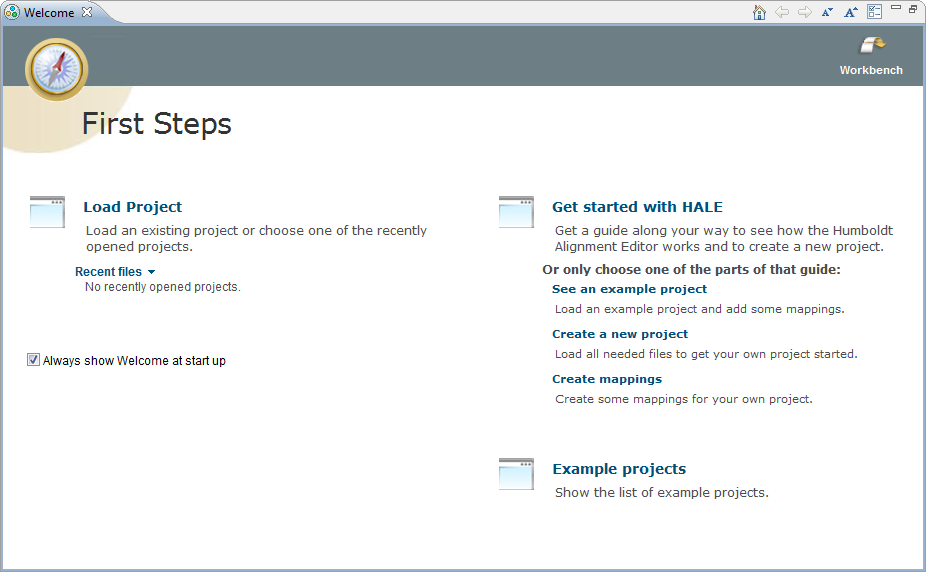
When first starting HALE you will be
greeted by a Welcome page which quickly gets you going on working
on an existing project or starting a new one. The guide gets you
started on the basic workflow when working with HALE.
|
| Integrated user guide |
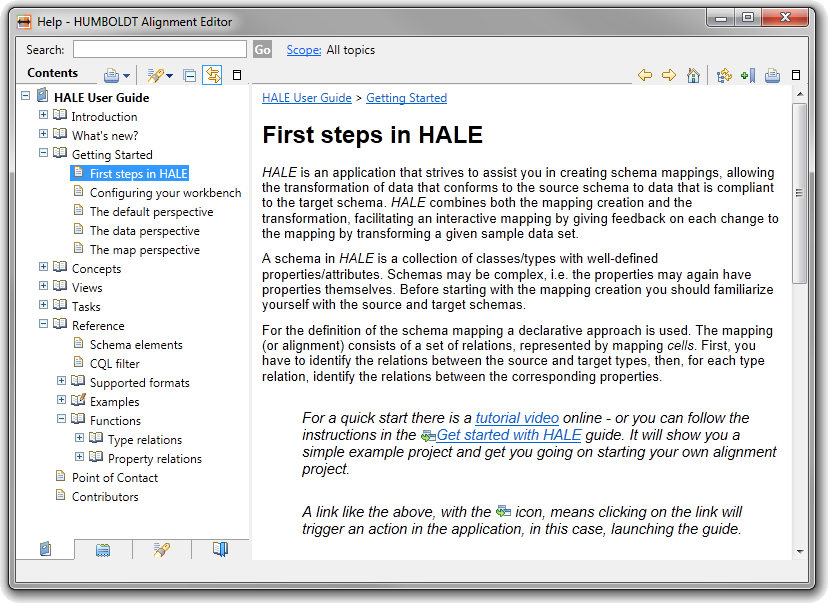
The integrated help can be launched through
the toolbar or the Help menu - it includes a user guide for HALE,
describing the main workflow, the different perspectives and views
and explains how to perform certain tasks and the concepts behind
them.
|
| Context-sensitive help |
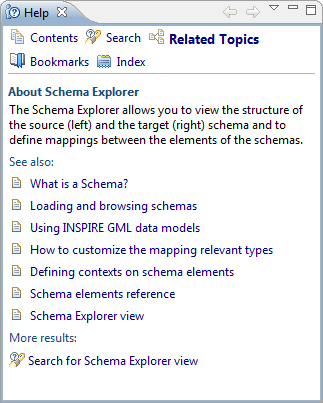
Pressing F1 will open a view with help
topics that are related to your active view and possibly even for
your current selection. For example, with a cell selected in the
alignment view, the help will provide you with the link to the
documentation of the related transformation function.
|
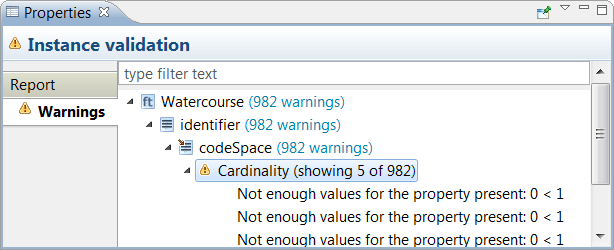
| Reports on performed actions |
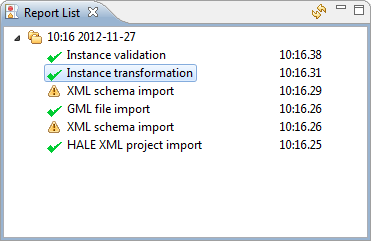
Actions like loading or saving data,
loading schemas, performing the transformation or exporting the
alignment produce a detailed report. Select a report in the Report
List view to access eventual warnings and errors that occurred
during the process in the Properties view.
|
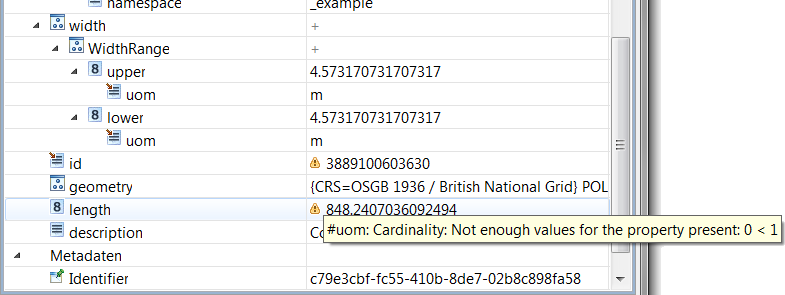
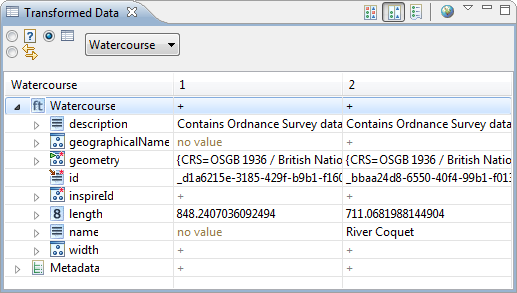
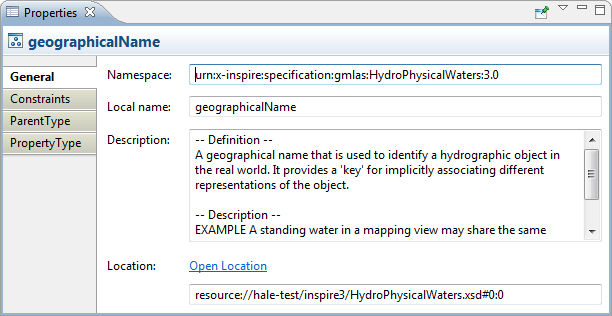
| Inspect selection in Properties view |
Detailed information on a selected object
is now displayed in the Properties view - currently this works for
schema elements, alignment cells, functions and reports.
Programmers can easily extend it with additional sections.
|
| Alignment view |
The Mapping Graph view has been reworked to
better integrate with the rest of the application and is now called
Alignment view. It renders the old mapping view obsolete, as
editing and deleting cells can now be performed on the alignment
view selection, and details on the selected cell are displayed in
the Properties view.
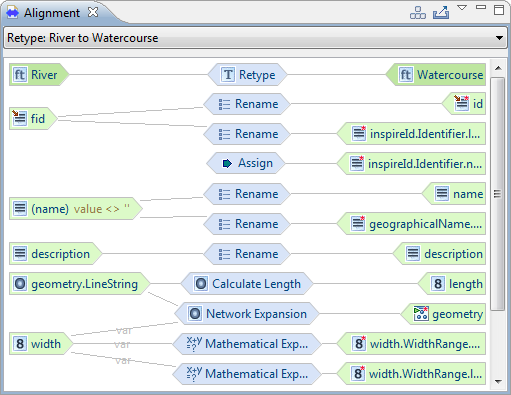
For more information, please have a look at the Alignment
view documentation.
|
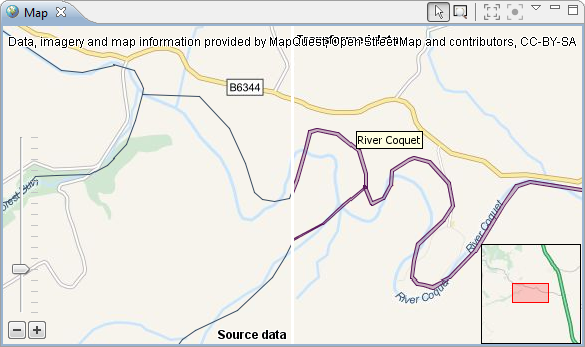
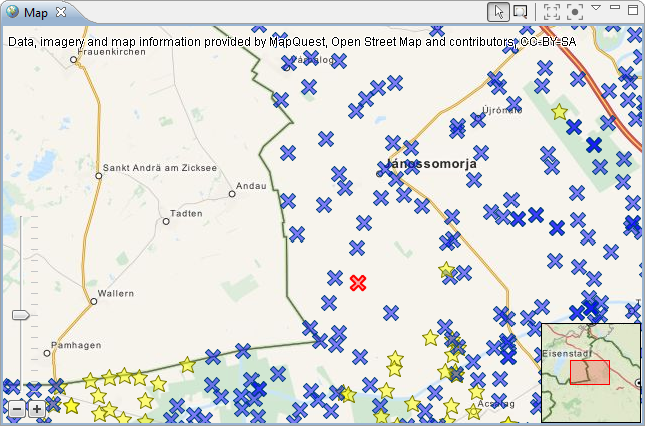
| New map view |
The map view has been replaced by a new
component that is able to put the data into context by displaying
it on a background map. By default, OpenStreetMap is used as the
background map. Instances in the map can be selected and their
style adapted with an integrated editor.
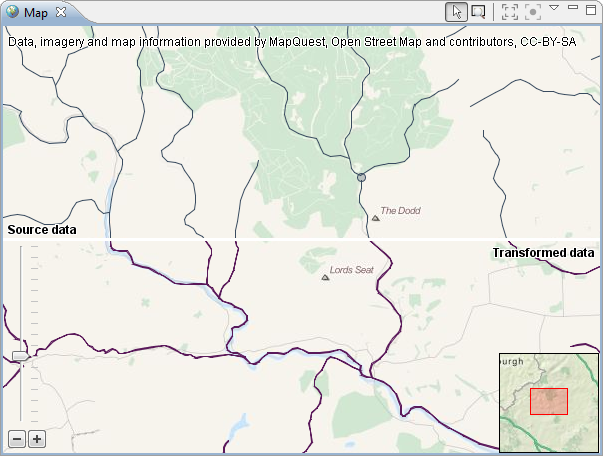
For more information, please have a look at the Map
view documentation.
|
| Merge instances of the same type |
A new type relation has been added, that
allows to merge multiple source instances of the same type, based
on an equal property value. The other properties are either merged
also, or all values of the property are available in the merged
instance.
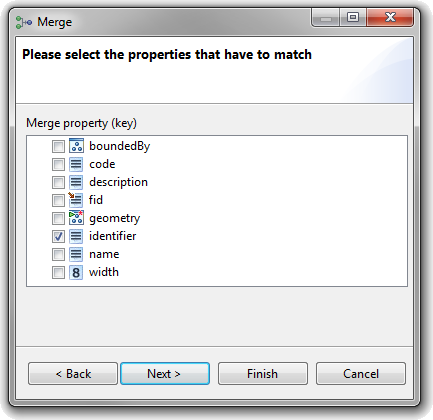
|
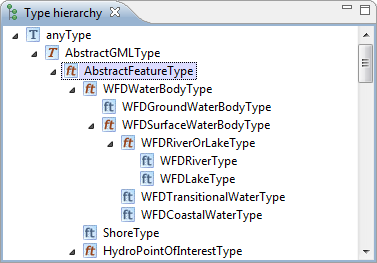
| Type Hierarchy view |
The new Type Hierarchy view can be used to
inspect the hierarchy of a specific schema type. Select a schema
element, e.g. in the Schema Explorer, and the associated type and
its super and sub-types will be displayed. You can focus on another
type in the hierarchy by double clicking on it.
|
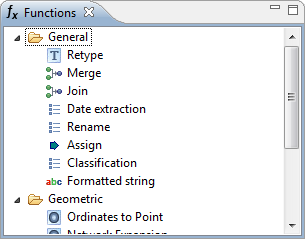
| Functions view |
Get an overview of the available
transformation functions. Detailed information on a selected
function can be obtained either through the Properties view or the
contextual help (pressing F1).
|
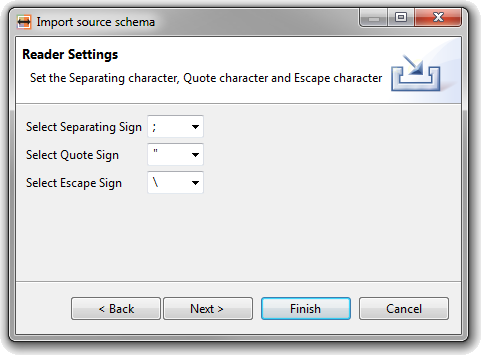
| Support for CSV files |
Comma Separated Value (CSV) files can now
be used as source schema and data. For the schema, column names can
either be used as available in the first row of the file, or
specified manually.
|
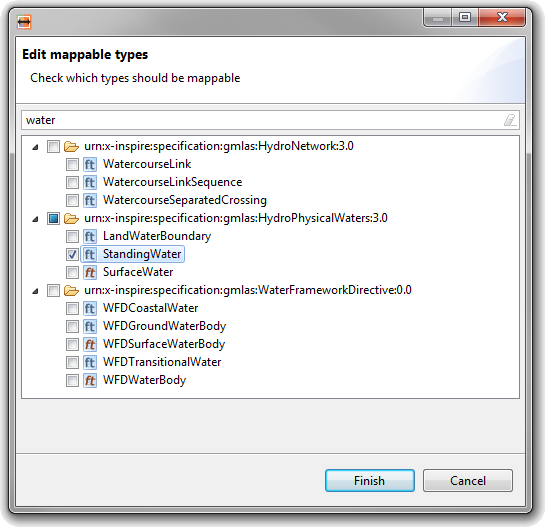
| Mapping relevant types |
Not all typed defined in a schema are
usually relevant for a mapping. Now you can customize which types
are relevant for your mapping in the source and target schemas -
thus, only those types are displayed in the Schema Explorer, and
only data instances of these types are loaded when loading source
data.
|
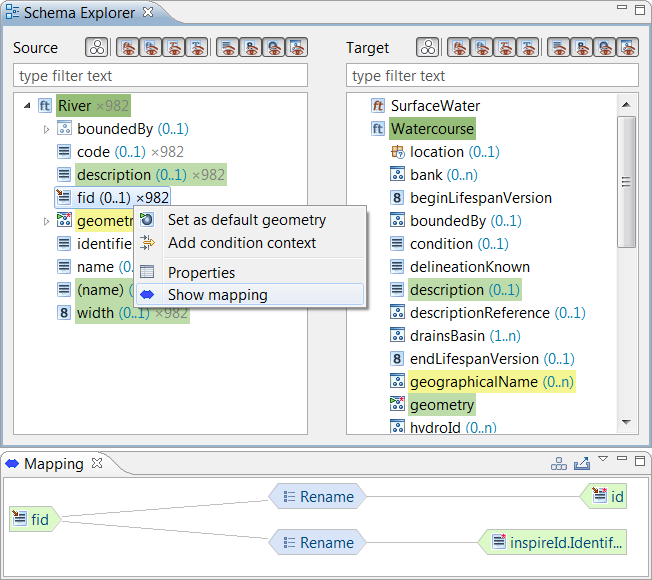
| Create contexts on schema elements |
A context on a schema element may represent
a condition applied to it, an element at a certain index or just an
additional instance of a target property that may be populated.
Contexts can be created for a selected schema element through the
context menu in the Schema Explorer, if applicable.
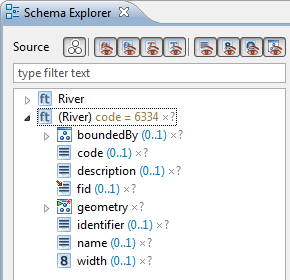
For more information, please have a look at the more detailed Contexts
documentation.
|
| Filters on nested properties |
Filters for use in the data views and
condition contexts have been improved to support specifying nested
properties. Use the Insert attribute name button to choose a
schema element and insert the corresponding name.
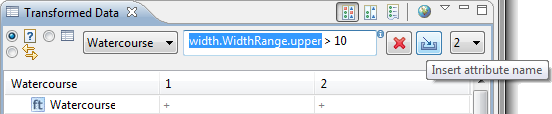
For more information, please have a look at the documentation on CQL
Filters.
|
| Cell explanations |
It is not always easy to grasp how a
transformation function works and what effect a defined relation
has. On a selected mapping cell you now get an explanation
(displayed in the Properties view) that expresses the relation in a
more human understandable way.
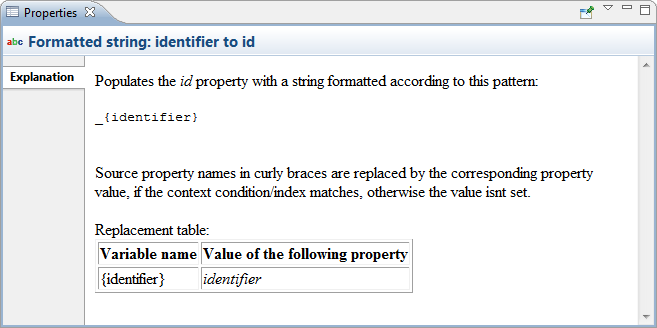
|
| Improved HTML mapping documentation |
The export of your mapping as a HTML file
presents you with a mapping documentation you can easily share.
First you get an overview of all type relations, then for each type
relation the relevant property relations, including their
explanation.
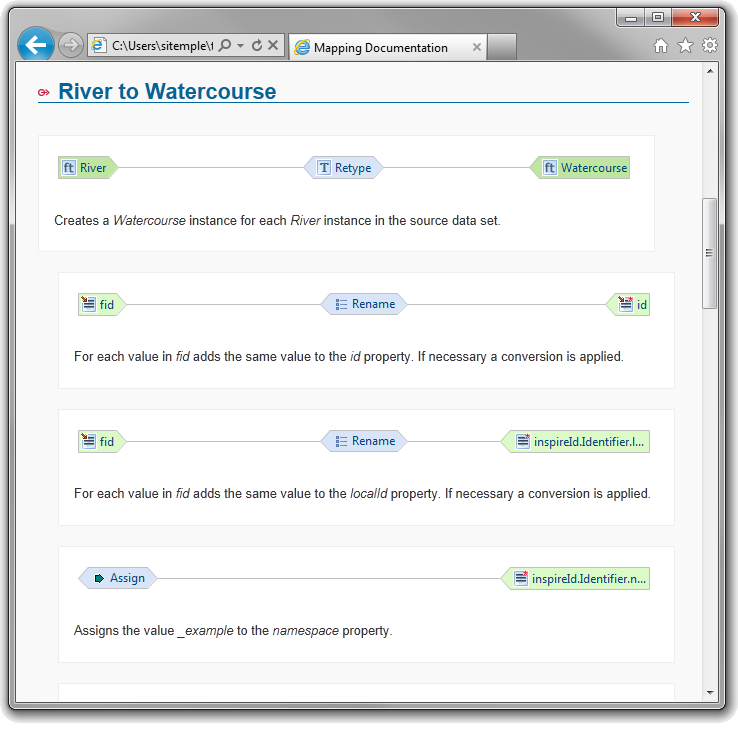
|
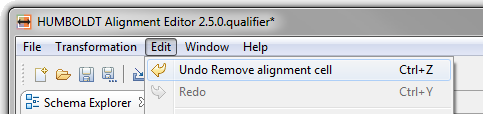
| Undo/Redo support |
When creating your mapping you now can undo
or redo the performed steps, like adding, replacing or deleting
cells.
|
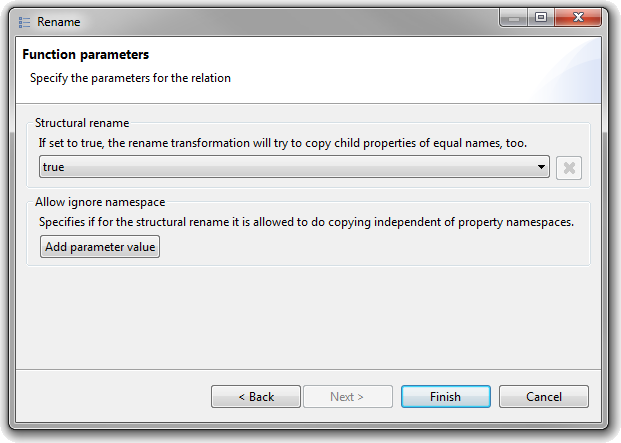
| Structural rename |
The Rename relation now supports copying a
complex structured property, given that the structure of the target
property is similar.
|
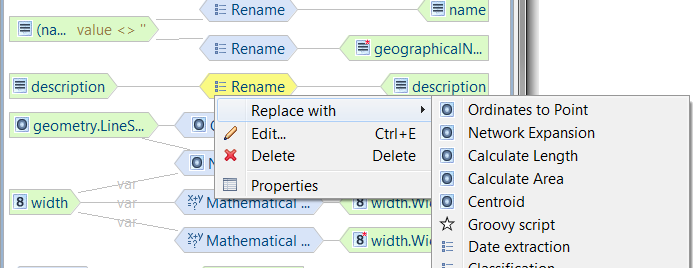
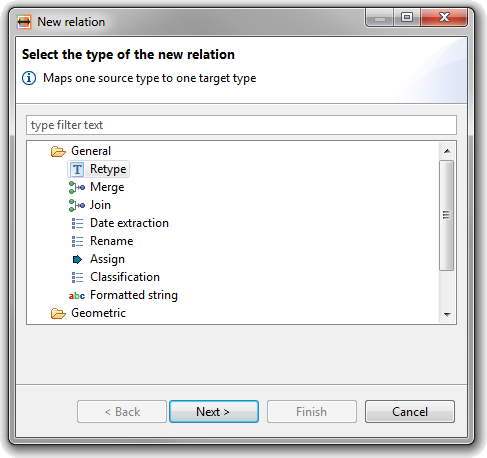
| Generic function wizard |
Instead of letting each transformation
function provide its own wizard for it to be configurable through
the user interface, setting the source and target entities and
specifying parameters is done through the generic function wizard.
This makes it a lot easier to extend HALE with new transformation
functions. If desired, functions can still provide their own wizard
pages for the parameter configuration.
|
Under
the Hood |
| New application architecture |
HALE has undergone a major restructuring of
the whole application, motivated by the following goals:
- Simple but flexible and extendable models for schema,
data and alignment
- Modular architecture that allows the use in different
environments (e.g. UI and Server)
- Common infrastructure for all I/O operations
- Support transformation of large data sets
- Allow to easily extend HALE with additional functionality
There are several extension points allowing HALE to be extended by
Plug-ins. Apart from the general UI extension points provided by
Eclipse RCP, which for instance allow you to add your own views,
these are some of the functionalities you can extend:
- Transformation function definitions and implementations
- Converters for automatic value conversion
- Import and export formats for schema, data, alignment
etc.
- Map tools, overlays, layouts and maps
- Instance representations in data views
- include online resources for offline use
|
| Internal database based on OrientDB |
Data now is stored in a temporary internal
database instead of being held in the memory all the time. This
allows to deal with bigger data sets, as only those instances
actually needed are retrieved from the database. Transformation can
be performed in a streaming like process, where loading data,
transformation and storing the transformation result are done in
parallel.

|
| Multiple schemas as source or target |
You can combine multiple schemas to form
your source and target schemas, for example an XML Schema together
with a Shapefile and a CSV file could form your source schema.
Currently there is one exception to this, you can't load multiple
XML Schemas into source or target. This is to prevent namespace
incompatibilities and duplicated schema elements - if you need to
use multiple XML Schemas, you can use the workaround as described here.
|
| Streaming XML and GML |
Generic XML and GML reader and writer that
support streaming, i.e. they read or write the data instance by
instance instead of all at once. |
| Conversion service and automated conversion |
A conversion service is provided as OSGi
service in the application and can be used for value conversions
and extended with custom converters. In addition, transformation
function results are automatically converted to the corresponding
target property type (if the function does not prohibit this). |
| New transformation service implementation |
The Conceptual Schema Transformer (CST) has
been reimplemented based on the new models. It is the default
transformation service implementation and uses a transformation
tree to handle the transformation of complex structures with
varying cardinalities. |
| Bundle schemas with HALE |
Plugins may extend HALE to provide schemas
for offline use. Some well-known schemas are already bundled with
HALE, e.g. the GML 3.2.1 schema, to speed up schema loading. |